
Handling documents efficiently is a critical requirement for many businesses. Extracting structured data from PDF files and storing it in a database can streamline operations in finance, legal, healthcare, and other industries. Azure AI Services provides robust tools for automating this process, including Azure AI Document Intelligence (formerly Form Recognizer) and Azure Cognitive Services.
In this blog, we’ll walk through how to:
- Read a PDF document
- Extract relevant data
- Store the extracted information in a database
Solution Overview
The solution involves the following components:
- Azure AI Document Intelligence – Extracts text, tables, and key-value pairs from PDFs.
- Azure Storage (Optional) – Stores uploaded PDF documents for processing.
- Azure Function or Web App – Handles document processing and extraction.
- Azure SQL Database or Cosmos DB – Stores the extracted data.
Architecture Diagram
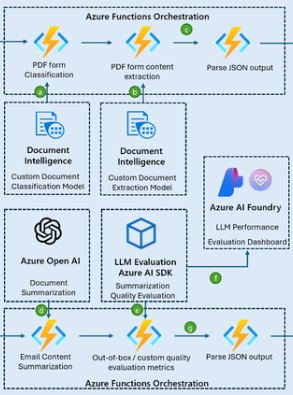
Step-by-Step Implementation
Step 1: Upload PDF to Azure Storage
Before processing, store the PDF in Azure Blob Storage for centralized access.
- Create an Azure Storage Account.
- Use Blob Storage to store PDFs.
- Generate a SAS (Shared Access Signature) URL for secure access.
Step 2: Extract Data Using Azure AI Document Intelligence
Azure AI Document Intelligence can extract structured data from PDFs, including invoices, receipts, business documents, and more.
Setting Up AI Document Intelligence
- Go to Azure Portal and create a Document Intelligence resource.
- Get the API Key and Endpoint URL.
- Use prebuilt models or train a custom model for specific document formats.
Code to Extract Data from PDF
import requests
import json
endpoint = "<your_document_intelligence_endpoint>"
api_key = "<your_api_key>"
file_url = "<pdf_file_sas_url>"
headers = {
"Ocp-Apim-Subscription-Key": api_key,
"Content-Type": "application/json"
}
data = {"urlSource": file_url}
response = requests.post(f"{endpoint}/formrecognizer/documentModels/prebuilt-document:analyze", headers=headers, json=data)
result = response.json()
print(json.dumps(result, indent=4))Step 3: Process Extracted Data
The API response contains:
- Extracted Text
- Tables
- Key-Value Pairs
Example of extracted data:
{
"documents": [
{
"fields": {
"InvoiceNumber": {"valueString": "INV-12345"},
"TotalAmount": {"valueNumber": 1250.75},
"Date": {"valueDate": "2024-03-15"}
}
}
]
}Step 4: Store Data in Azure SQL Database
Once data is extracted, store it in Azure SQL Database or Cosmos DB for further processing.
Example: Storing Data in SQL Database
import pyodbc
server = "your-sql-server.database.windows.net"
database = "your-db"
username = "your-username"
password = "your-password"
driver = "{ODBC Driver 17 for SQL Server}"
conn = pyodbc.connect(f'DRIVER={driver};SERVER={server};DATABASE={database};UID={username};PWD={password}')
cursor = conn.cursor()
cursor.execute("INSERT INTO Invoices (InvoiceNumber, TotalAmount, Date) VALUES (?, ?, ?)",
("INV-12345", 1250.75, "2024-03-15"))
conn.commit()Step 5: Automate with Azure Functions
To automate PDF processing:
- Trigger Azure Function when a new file is uploaded.
- Call Document Intelligence API to extract data.
- Store extracted data in a database.
Azure Function can be triggered using Event Grid when a PDF is uploaded to Blob Storage.
Key Takeaways:
✅ Use Azure AI Document Intelligence to extract structured data from PDFs.
✅ Store files securely in Azure Blob Storage.
✅ Automate processing using Azure Functions.
✅ Store extracted information in Azure SQL Database or Cosmos DB.
With this approach, businesses can automate data extraction, reduce manual work, improve accuracy, and enhance document management workflows.
Extra posts:
 Unlocking the Power of AI with Azure Cognitive Services
Unlocking the Power of AI with Azure Cognitive Services  Enhancing Copilot Bots with Azure OpenAI Services
Enhancing Copilot Bots with Azure OpenAI Services  A Complete Guide to Azure Database Migration Strategies, Tools, and Best Practices
A Complete Guide to Azure Database Migration Strategies, Tools, and Best Practices  Mastering Event Sourcing in Azure Storing System State as a Sequence of Events
Mastering Event Sourcing in Azure Storing System State as a Sequence of Events  Top 7 Azure Services You Didn’t Know You Needed
Top 7 Azure Services You Didn’t Know You Needed  Top 10 Azure Services Everyone Should Know (2025 Edition)
Top 10 Azure Services Everyone Should Know (2025 Edition)