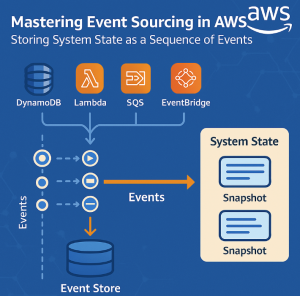
Modern applications demand scalability, traceability, and resilience — characteristics that traditional CRUD-based systems often struggle to deliver. That’s where Event Sourcing shines. It’s an architectural pattern that stores every change to application state as an immutable event, allowing you to reconstruct any past state and support powerful features like auditing, debugging, and complex workflows.
In this article, we’ll explore how to implement Event Sourcing on AWS, leveraging services like Amazon DynamoDB, Kinesis, S3, Lambda, and more.
🔁 What Is Event Sourcing?
In a traditional system, the current state is stored directly — for example, in a relational database row. In contrast, Event Sourcing stores a series of domain events that represent every state change over time.
Example events:
AccountCreatedFundsDepositedFundsWithdrawn
To derive the current balance, the system replays all events for a given account.
☁️ Why Use Event Sourcing on AWS?
AWS offers a rich ecosystem of scalable, pay-as-you-go services that make Event Sourcing practical, performant, and cost-efficient:
- Amazon DynamoDB: For fast, serverless event storage.
- Amazon S3: For cold storage of large event logs.
- Amazon Kinesis / EventBridge: For real-time event streaming.
- AWS Lambda: For processing and projecting events into read models.
- Amazon SNS/SQS: For pub/sub or queue-based architectures.
- Amazon Aurora / RDS: For building query-optimized read views.
With these tools, you can build a decoupled, resilient, and scalable event-sourced system.
🧱 Typical Architecture on AWS
Here’s how a typical event-sourced architecture looks in AWS:
- Command Receivers: API Gateway + Lambda accept and validate commands.
- Event Creators: Validated commands become domain events.
- Event Store: Events are persisted in DynamoDB (or S3 for long-term storage).
- Event Publisher: Events are pushed to Kinesis or EventBridge.
- Event Handlers / Projectors: AWS Lambda functions process events and update materialized views in DynamoDB or Aurora.
- Query Layer: Read models are exposed via Lambda-backed APIs or GraphQL with AppSync.
🛠️ Implementing Event Sourcing on AWS
1. Storing Events in DynamoDB
Each event is written as an item to a DynamoDB table with keys like:
jsonCopyEdit{
"aggregateId": "account-123",
"eventId": "uuid",
"eventType": "FundsDeposited",
"timestamp": "2025-07-27T14:30:00Z",
"data": {
"amount": 500
}
}
Partition by aggregateId and sort by timestamp or a sequence number for fast replay.
2. Publishing Events
Use Amazon Kinesis, EventBridge, or SNS to publish events for further processing.
Kinesis example:
- A Lambda function writes events to Kinesis.
- Downstream Lambda consumers receive batched events and update projections.
3. Building Read Models (Projections)
Each event triggers a Lambda function that updates a read model in DynamoDB, Aurora, or ElastiCache.
This decouples reads from the write model and allows each read model to be optimized for specific query patterns.
4. Event Replay & Snapshots
To speed up recovery:
- Periodically take snapshots of aggregates (stored in S3 or DynamoDB).
- On replay, load the last snapshot and apply only newer events.
✅ Benefits of Event Sourcing on AWS
- Auditability: Every change is recorded with a timestamp.
- Resilience: Events can be replayed to recover state or populate new services.
- Scalability: AWS services like Kinesis and DynamoDB scale seamlessly.
- Polyglot Projections: Build multiple read models from the same event stream.
- Integration Friendly: Easily integrate with external systems via EventBridge or SNS.
⚠️ Challenges to Consider
- Event Versioning: Plan for schema evolution.
- Idempotency: Ensure projections handle repeated events safely.
- Event Ordering: Use consistent partitioning to preserve order.
- Data Volume: Event logs grow indefinitely — use S3 for archival storage.
- Consistency: Achieve eventual consistency between write and read models.
🧩 Best Practices
- Use DynamoDB Streams to trigger projections without polling.
- Add metadata to events (e.g., correlation IDs, user IDs) for observability.
- Introduce event schemas (using AWS Glue Schema Registry or JSON Schema).
- Use S3 Lifecycle Policies to archive old event data cost-effectively.
- Create snapshot Lambda functions to generate periodic state captures.
🧪 Sample Use Case: Banking Application
- User initiates
DepositFundsvia API Gateway → Lambda. - Lambda validates input and stores
FundsDepositedevent in DynamoDB. - Event is sent to Kinesis stream.
- A Lambda projector reads the event and updates a balance read model in DynamoDB.
- The client queries the balance via a separate Lambda or AppSync GraphQL API.
This setup gives you real-time projections, full audit logs, and replay capability — with minimal infrastructure management.
Event Sourcing is a powerful pattern that unlocks traceability, auditability, and flexibility in modern applications. When implemented with AWS serverless and managed services, it becomes even more compelling.
With DynamoDB, Lambda, Kinesis, and S3, AWS provides all the building blocks to create a reliable and scalable event-sourced system without managing servers or complex infrastructure.
Extra posts:
 Mastering Event Sourcing in Azure Storing System State as a Sequence of Events
Mastering Event Sourcing in Azure Storing System State as a Sequence of Events  🚀 Materialized View Pattern in AWS Precompute for Performance
🚀 Materialized View Pattern in AWS Precompute for Performance  Building Resilient Systems with Immutable Infrastructure on AWS
Building Resilient Systems with Immutable Infrastructure on AWS  Token-Based Authentication in AWS Using JWT for Stateless Security
Token-Based Authentication in AWS Using JWT for Stateless Security  CQRS on AWS Separating Read and Write Operations for Performance and Scalability Secret Store Pattern in AWS Using Secure Vaults for Credentials and Secrets
CQRS on AWS Separating Read and Write Operations for Performance and Scalability Secret Store Pattern in AWS Using Secure Vaults for Credentials and Secrets